
💡 LPU가 AI 추론의 게임 체인저가 되는 이유
2026년 엔비디아 GTC에서 발표된 LPU(Language Processing Unit)는 단순한 새로운 가속기가 아닌 AI 추론 패러다임의 근본적 변화를 의미합니다. ✨ 기존 GPU 중심의 컴퓨팅에서 메모리 계층별 최적화로 전환하는 핵심 기술로, 특히 트랜스포머 모델의 디코드(decode) 단계에서 발생하는 레이턴시 문제를 해결합니다. LPU는 온칩 S램을 활용해 초당 40TB의 압도적 대역폭을 제공하며, 이는 HBM4의 22TB보다 훨씬 높은 수치로 빠른 토큰 생성을 가능하게 합니다.
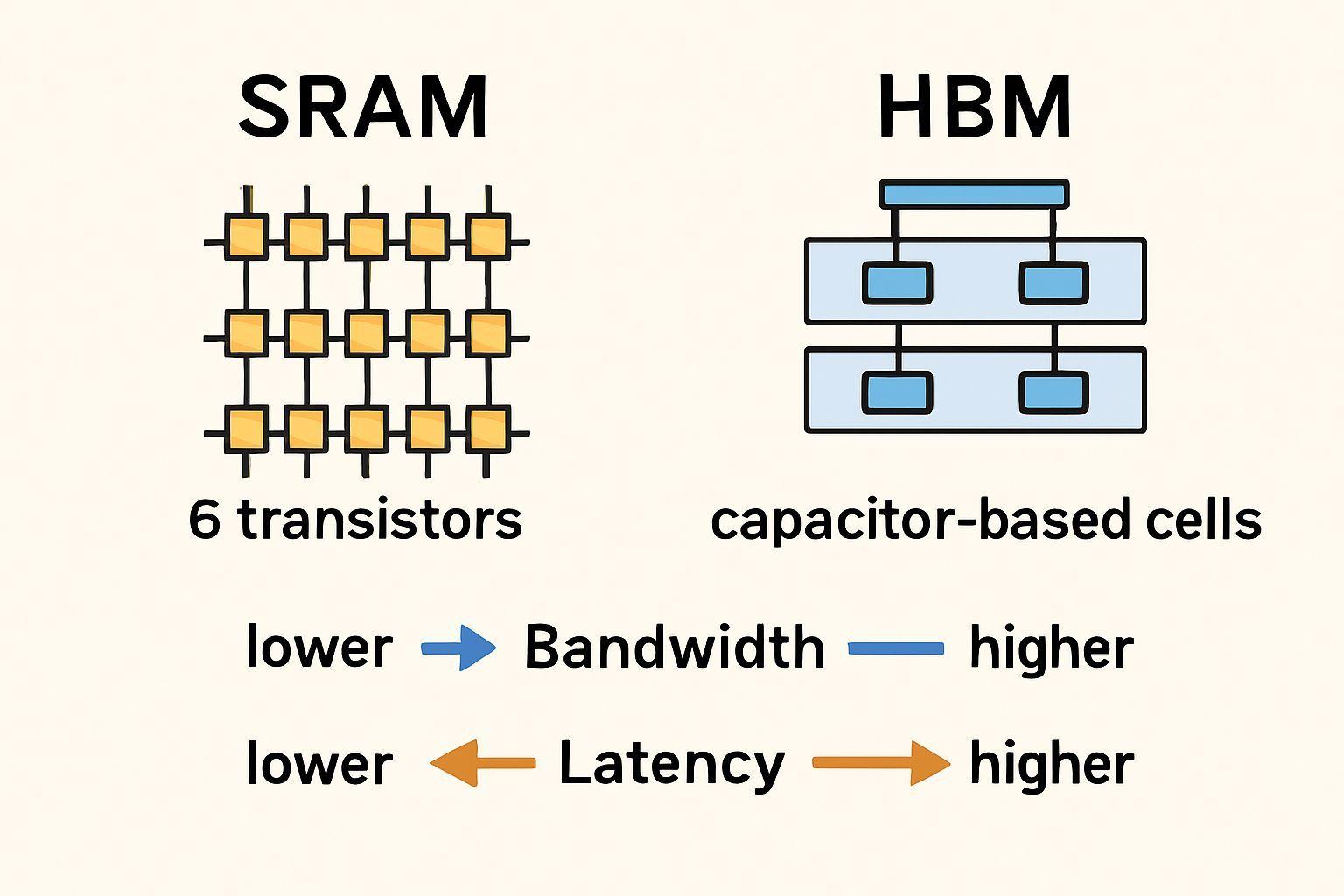
🔍 S램 vs HBM: 용량과 속도의 트레이드오프
AI 추론에서 메모리 선택은 이제 단순한 용량 문제가 아닌 작업 특성에 맞는 계층적 접근이 필수입니다. 📈 S램은 작은 용량(500MB)에도 초당 150TB의 높은 대역폭으로 레이턴시 민감 작업에 적합한 반면, HBM은 대용량(288GB) 저장과 긴 시퀀스 처리를 담당합니다. 이러한 구분은 비용 효율성 때문인데, S램은 로직 반도체 공정으로 제작되어 면적 대비 비싸지만 빠른 접근 속도를, HBM은 별도 메모리 공정으로 대용량을 경제적으로 제공합니다.
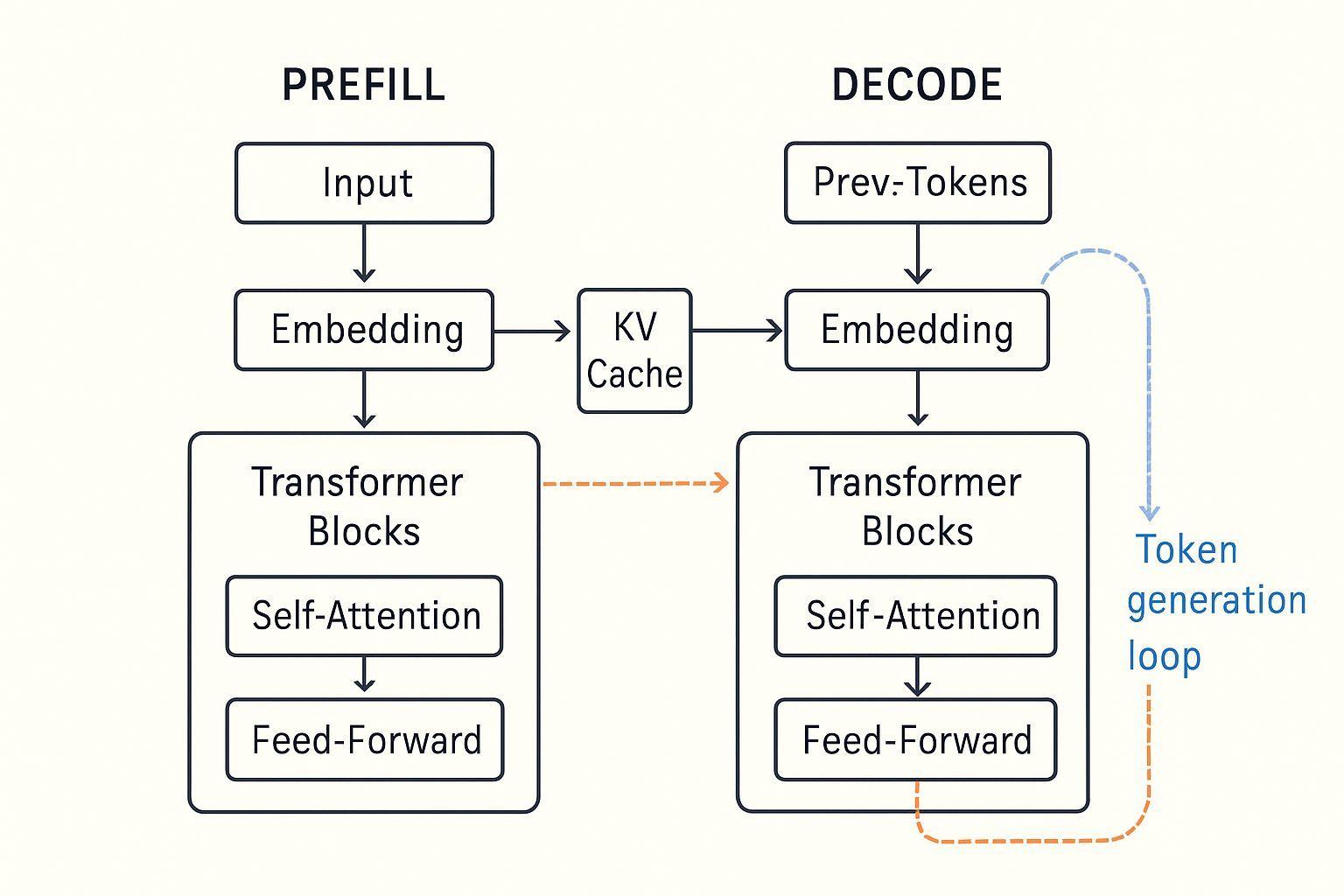
⚙️ 프리필과 디코드: 트랜스포머의 두 얼굴
트랜스포머 모델의 작동 방식을 이해하면 LPU의 필요성이 명확해집니다. 💡 프리필(prefill) 단계는 긴 입력 시퀀스를 한 번에 처리해 KV 캐시를 생성하는 대형 행렬 연산으로, HBM의 고대역폭과 대용량이 유리합니다. 반면 디코드(decode) 단계는 토큰을 하나씩 생성하는 짧은 반복 루프로, 결정론적 실행과 낮은 레이턴시가 핵심이며 이 부분이 LPU의 S램이 담당하는 영역입니다.
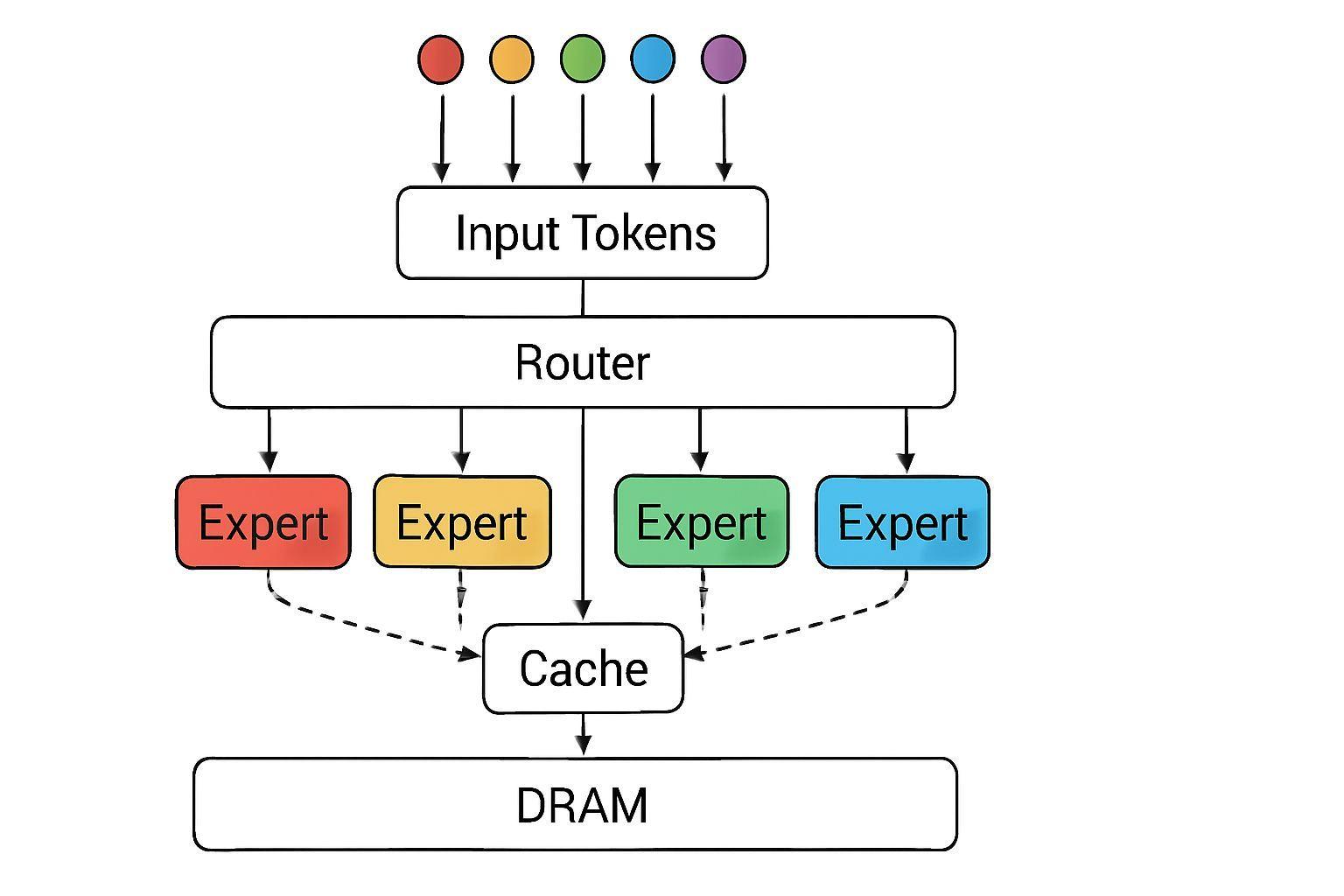
📈 MOE 시대의 메모리 계층 전쟁
Mixture of Experts(MOE) 아키텍처의 부상은 메모리 계층 최적화를 더욱 중요하게 만들었습니다. 🔄 MOE 모델에서는 토큰별 전문가(Expert) 라우팅이 추가되어 기존 댄스(dense) 모델보다 통신 오버헤드가 증가합니다. 이 때문에 엔비디아는 디코드 어텐션을 루빈 GPU에, FFN과 MOE Expert Execution을 LPU에 분담시켜 각각 HBM과 S램의 장점을 극대화하는 전략을 채택했습니다.
✅ 핵심 요약 Q&A
Q: LPU가 기존 GPU와 근본적으로 다른 점은 무엇인가요? A: 단순 컴퓨팅 성능 향상이 아닌 메모리 계층별 최적화로, 특히 디코드 단계의 레이턴시 문제를 S램의 고대역폭으로 해결합니다. Q: S램과 HBM은 어떤 상황에서 각각 사용되나요? A: S램은 빠른 토큰 생성이 필요한 디코드 루프에, HBM은 대용량 데이터 처리와 긴 시퀀스 프리필에 최적화되어 있습니다. Q: 메모리 계층 분할이 AI 추론에 어떤 이점을 제공하나요? A: 작업 특성에 맞는 메모리 사용으로 전력 효율 향상, 비용 최적화, 그리고 평균 응답 시간 개선을 동시에 달성할 수 있습니다. Q: MOE 아키텍처가 메모리 계층 중요성을 높인 이유는? A: 전문가 라우팅으로 인한 통신 오버헤드 증가로 인해 데이터 이동 경로 최적화가 컴퓨팅 성능보다 더 중요한 요소가 되었기 때문입니다. Q: 2026년 AI 추론 시장의 주요 변화는 무엇인가요? A: 단일 하드웨어 성능 경쟁에서 메모리 계층, 스케일업 패브릭, 전문가 스케줄링이 통합된 시스템 아키텍처 경쟁으로 패러다임이 전환되었습니다.


