
💡 터보컨트와 KV 캐시 압축의 필요성
터보컨트(TurboQuant)는 구글이 발표한 KV 캐시 압축 방식으로, 대규모 AI 모델의 메모리 병목 현상을 해결하려는 혁신적인 시도입니다. 🤯 AI 모델이 복잡해지고 대화가 길어질수록 KV 캐시의 양은 기하급수적으로 늘어나 HBM과 같은 고성능 메모리에 큰 부담을 줍니다. 이러한 문제를 해결하기 위해 터보컨트는 최소 6배의 메모리 절감과 최대 8배의 컴퓨팅 가속을 약속하며 큰 주목을 받고 있습니다. 하지만 이 기술이 거대한 대형 AI 모델에서도 동일하게 성공할 수 있을지는 여전히 중요한 질문으로 남아 있습니다.
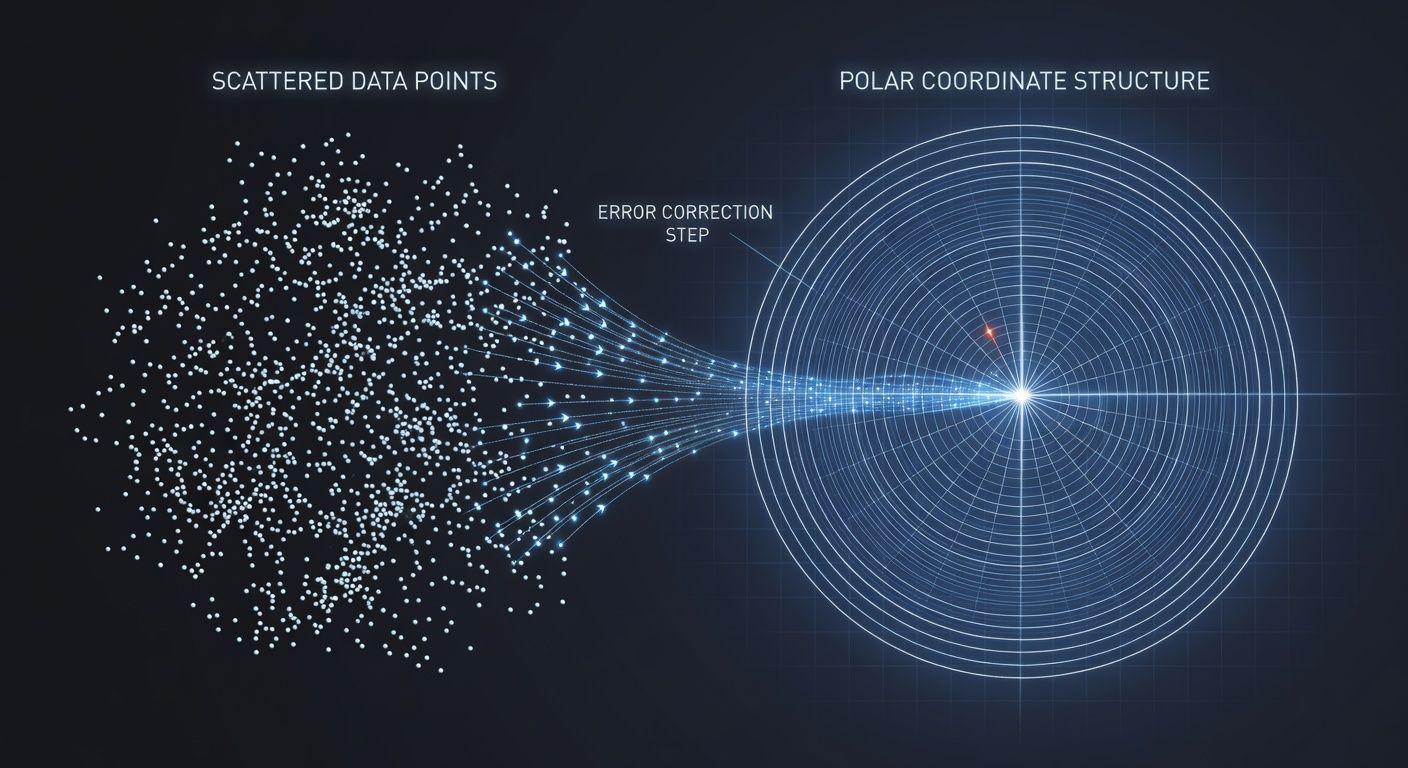
⚙️ 터보컨트의 작동 방식: 폴라 컨트와 QJL
터보컨트의 핵심은 두 단계 압축 방식에 있습니다. 첫 번째는 ‘폴라 컨트(Polar Quant)’로, 데이터 벡터를 랜덤하게 회전시켜 극좌표계로 변환한 후 각도 정보만 양자화하여 대폭 압축하는 방식입니다. 🛠️ 이는 기존의 단순한 정수 비트 낮춤 방식과 달리, 어텐션 스코어 계산에 중요한 벡터 간의 관계성을 유지하며 데이터를 효율적으로 정리합니다. 두 번째 단계는 ‘QJL’이라는 오차 보정 메커니즘으로, 폴라 컨트 과정에서 발생할 수 있는 잔여 오차를 단 1비트만 사용하여 보정합니다. 이 1비트는 오차의 ‘방향성’을 파악해 어텐션 스코어가 한쪽으로 치우치는 현상을 효과적으로 줄여줍니다.
🔍 대형 AI 모델에서의 터보컨트 적용 과제
터보컨트의 논문은 작은 AI 모델에서 뛰어난 성능을 보였지만, 대형 모델에서의 적용은 또 다른 문제입니다. 🚨 특히 트랜스포머 기반의 대형 모델은 레이어가 많고 컨텍스트 길이가 길어질수록 초기 양자화 과정에서 발생한 작은 오차가 누적되어 최종 결과에 큰 왜곡을 가져올 수 있는 ‘오차 전파(Error Propagation)’ 위험이 있습니다. 2025년 연구에 따르면, 짧은 컨텍스트용 KV 캐시 양자화 방식을 대형 LLM에 적용했을 때 성능 저하가 명확히 나타난 사례도 있습니다. KV 캐시의 ‘Key’ 값은 밸류보다 훨씬 민감하여, 이곳에 오차가 생기면 엉뚱한 정보를 참조할 수 있어 모델의 정확성이 크게 저해될 수 있습니다.

📈 하드웨어 구현과 지속적인 연구의 중요성
터보컨트의 성공적인 상용화를 위해서는 하드웨어 아키텍처 구현이 필수적입니다. 데이터를 극좌표로 변환하고 다시 복원하는 과정은 분명 컴퓨팅 오버헤드를 발생시키지만, ⚙️ 파이프라이닝 기법을 통해 이러한 지연 시간을 효과적으로 숨길 수 있을 것으로 기대됩니다. 하지만 KV 캐시가 대형 모델에서 얼마나 규칙적으로 처리될지, 그리고 QJL의 1비트 보정이 큰 모델에서도 효과적일지는 추가적인 검증이 필요합니다. 궁극적으로는 얼마나 똑똑하게 압축하고, 압축된 정보를 얼마나 효율적으로 재사용할 수 있는지가 관건이며, 터보컨트 이후에도 프로그레시브 양자화 등 다양한 후속 연구가 계속되고 있습니다.
✅ 핵심 요약 Q&A
Q: 터보컨트(TurboQuant)는 무엇인가요? A: 구글이 발표한 KV 캐시 압축 기술로, AI 모델의 메모리 사용량과 컴퓨팅 속도를 최적화하는 것을 목표로 합니다. Q: KV 캐시 압축이 왜 중요한가요? A: 대형 AI 모델과 긴 대화에서 KV 캐시 메모리 사용량이 급증하여 성능 병목의 주요 원인이 되기 때문입니다. Q: 터보컨트의 핵심 작동 방식은? A: ‘폴라 컨트’로 극좌표 변환 후 각도 양자화를 통해 크게 압축하고, ‘QJL’로 잔여 오차를 1비트로 보정하는 2단계 방식입니다. Q: 대형 AI 모델에서의 적용 시 문제는? A: 작은 모델에서 검증된 성능이 대형 모델에서 ‘오차 전파’ 등으로 인해 저하될 수 있어 추가 검증이 필요합니다. Q: 향후 연구 방향은? A: 터보컨트를 포함한 KV 캐시 압축 기술은 대형 모델의 효율성을 높이는 중요한 과제로, 하드웨어 구현 및 다양한 후속 연구가 지속될 예정입니다.


