{"prompt":"A futuristic digital illustration showing the Google Gemma 4 logo floating above a globe with multiple language symbols radiating from it, representing its multilingual capabilities. In the background, small mobile devices transition to larger workstations, symbolizing the model's scalability across different hardware.","originalPrompt":"A futuristic digital illustration showing the Google Gemma 4 logo floating above a globe with multiple language symbols radiating from it, representing its multilingual capabilities. In the background, small mobile devices transition to larger workstations, symbolizing the model's scalability across different hardware.","width":1024,"height":576,"seed":42,"model":"zimage","enhance":true,"negative_prompt":"undefined","nofeed":false,"safe":false,"quality":"medium","image":[],"transparent":false,"audio":true,"has_nsfw_concept":false,"concept":null,"trackingData":{"actualModel":"zimage","usage":{"completionImageTokens":1,"totalTokenCount":1}}}
✅ 구글 젬마 4: 혁신적인 오픈 모델의 출현
2026년, 구글이 드디어 기다리던 젬마 4를 공개했습니다. 이 오픈 모델은 20억, 40억 파라미터의 작은 모델부터 MOE 방식의 260억, 댄스 모델 310억까지 네 가지 라인업으로 구성되어 있어 스마트폰부터 워크스테이션까지 다양한 환경에 최적화되었습니다. 젬마 4의 가장 큰 특징은 작은 크기에서도 놀라운 성능을 발휘한다는 점입니다. 특히 140개 이상의 언어를 지원하며 Apache 2 라이선스로 산업적으로 자유롭게 활용할 수 있어 많은 관심을 받고 있습니다. 작은 모델은 128K, 큰 모델은 256K의 컨텍스트 길이를 지원해 실용성이 크게 향상되었죠. 💡

💡 애플 하드웨어와 MLX: 온디바이스 AI의 최적화
젬마 4의 온디바이스 실행에는 애플의 M5 Pro 맥북 프로(64GB)와 M4 Pro 맥미니(48GB) 같은 하드웨어가 중요한 역할을 합니다. 애플의 유니파이드 메모리 아키텍처는 CPU, GPU, 뉴럴 엔진이 모두 동일한 메모리 풀을 공유해 데이터 이동 시간을 크게 줄여줍니다. MLX 프레임워크는 애플 실리콘에 최적화되어 젬마 4를 더 빠르고 효율적으로 실행할 수 있게 합니다. M5 Pro의 경우 307GB/s의 메모리 대역폭을 제공하며, 뉴럴 액셀러레이터가 트랜스포머 모델의 어텐션 연산을 가속화합니다. 이렇게 하드웨어와 소프트웨어가 결합되면 초당 125토큰 이상의 빠른 처리 속도를 달성할 수 있습니다. ✨

🔍 젬마 4 모델 라인업: 용도별 선택지
젬마 4는 사용 환경과 용도에 따라 네 가지 모델을 제공합니다. 이펙티브 20억과 40억 모델은 모바일 환경에 최적화되어 있으며, 128K 컨텍스트 길이로 에이전트 AI 작업에 적합합니다. MOE 방식의 260억 모델은 추론 시 실제로 40억 파라미터만 활성화되는 효율적인 구조로, 온디바이스에서 실행 가능한 최고 품질의 모델입니다. 310억 댄스 모델은 전체 파라미터가 활성화되어 더 높은 성능을 제공하지만, 더 많은 컴퓨팅 자원이 필요합니다. 이러한 분화된 라인업은 사용자가 자신의 하드웨어와 애플리케이션 요구사항에 맞게 선택할 수 있게 해줍니다. 📊
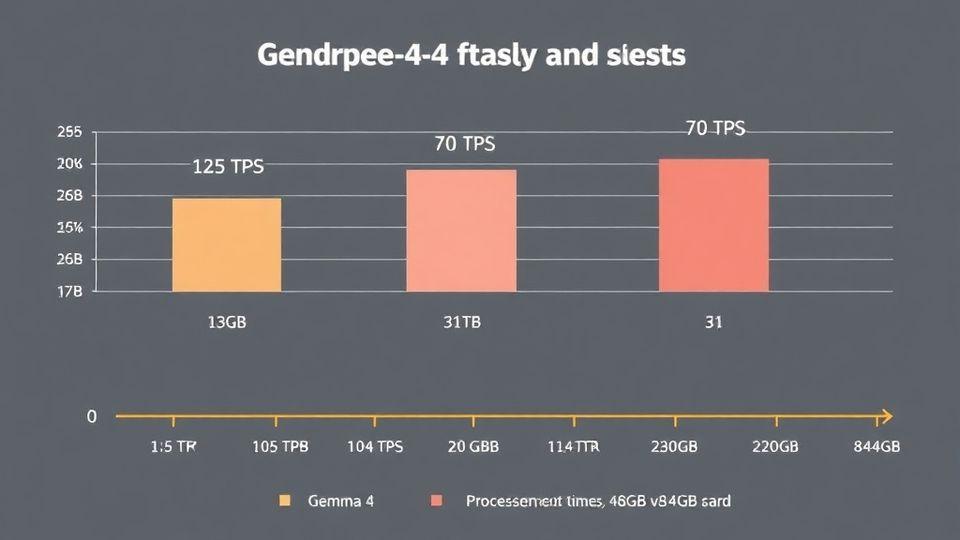
📈 성능 비교: 토큰 속도와 메모리의 영향
실제 테스트에서 M5 Pro 맥북 프로(64GB)는 젬마 4 20억 모델로 초당 125토큰의 빠른 속도를 보였습니다. 260억 MOE 모델도 초당 70토큰 이상의 성능을 발휘했죠. 반면 310억 댄스 모델은 초당 15토큰 정도로 상대적으로 느렸습니다. 대용량 컨텍스트 처리에서는 메모리 용량의 중요성이 두드러집니다. 50K 토큰 입력 시 64GB와 48GB 시스템 간 40초 차이가 발생했으며, 230K 토큰에서는 처리 시간 차이가 더욱 커졌습니다. 이는 KV 캐시 저장과 컨텍스트 관리에 더 큰 메모리가 유리하다는 것을 보여줍니다. 📊
✅ 핵심 요약 Q&A
Q: 젬마 4의 가장 큰 장점은 무엇인가요? A: 작은 크기에서도 뛰어난 성능과 140개 이상의 언어 지원, Apache 2 라이선스로 자유로운 상용화가 가능합니다. Q: 어떤 애플 하드웨어가 젬마 4 실행에 적합한가요? A: M5 Pro 맥북 프로(64GB)나 M4 Pro 맥미니(48GB)처럼 유니파이드 메모리가 충분한 애플 실리콘 기기가 최적입니다. Q: 젬마 4 모델 중 온디바이스 에이전트 AI에 가장 적합한 모델은? A: MOE 방식의 260억 모델이 실제 40억 파라미터만 활성화되어 빠른 응답 속도와 높은 품질을 동시에 제공합니다. Q: 온디바이스 AI의 주요 이점은 무엇인가요? A: API 호출 비용 절감, 개인 정보 보호, 낮은 지연 시간, 그리고 오프라인에서도 AI 기능 사용이 가능합니다. Q: 대용량 컨텍스트 처리 시 중요한 요소는? A: 메모리 용량과 대역폭이 KV 캐시 관리와 처리 속도에 직접적인 영향을 미치므로 충분한 RAM이 필수입니다. 💰




