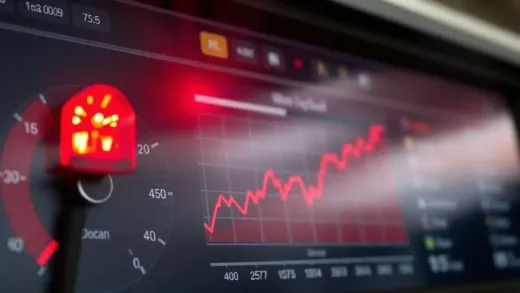
엔비디아의 아성에 도전하는 새로운 강자, 세레브라스
엔비디아의 독주 체제에 균열을 낼 만한 엄청난 AI 칩이 등장했습니다. 바로 ‘세레브라스(Cerebras)’가 공개한 WSE-3(Wafer-Scale Engine 3)입니다. 이 칩은 엔비디아 H100 GPU보다 무려 57배나 큰 크기를 자랑하며, HBM 메모리 없이도 초당 1,800 토큰이라는 경이로운 추론 속도를 보여줍니다. 이는 1초에 약 1,000단어에 가까운 텍스트를 생성하는 속도입니다. 기존 AI 칩들이 HBM이라는 고성능 메모리에 의존했던 것과 달리, 세레브라스는 ‘웨이퍼 전체를 하나의 칩’으로 만드는 혁신적인 접근 방식을 통해 메모리 병목 현상을 해결하고 AI 시장의 판도를 바꾸려 하고 있습니다.
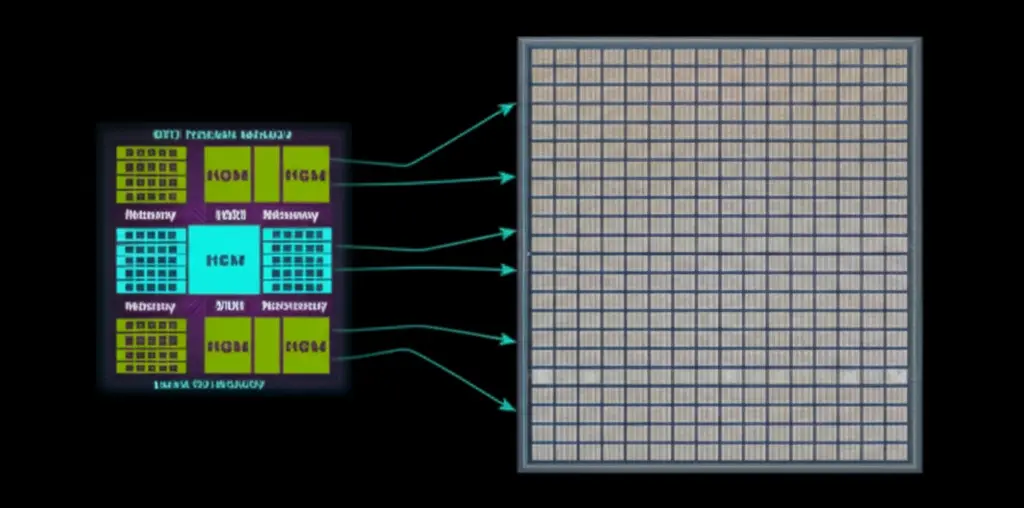
압도적인 속도의 비밀: 온칩 메모리와 웨이퍼 스케일
세레브라스 WSE-3의 속도 비밀은 ‘온칩 메모리(On-chip Memory)’에 있습니다. 엔비디아 GPU는 칩 외부에 HBM이라는 별도의 메모리를 두고 데이터를 주고받는 ‘오프칩(Off-chip)’ 구조입니다. 이 과정에서 데이터가 이동하는 물리적인 거리와 시간 때문에 성능 저하, 즉 ‘메모리 병목 현상’이 발생할 수밖에 없습니다. 반면 세레브라스는 SRAM이라는 초고속 메모리를 무려 44GB나 칩 내부에 직접 통합했습니다. 반도체 웨이퍼 전체를 하나의 거대한 칩으로 활용했기에 가능한 설계입니다. 덕분에 데이터가 칩 밖으로 나갈 필요 없이 내부에서 모든 처리가 이루어져, 메모리 대역폭이 엔비디아 대비 7,000배나 빠르다는 놀라운 결과를 만들어냈습니다.

왜 이런 극단적인 설계를 선택했을까?
웨이퍼 스케일 칩은 수율 문제와 높은 생산 비용 때문에 비효율적이라는 지적이 많습니다. 그럼에도 세레브라스가 이런 방식을 고집하는 이유는 AI 모델의 미래를 내다본 철학 때문입니다. GPT-5처럼 AI 모델이 점점 더 거대해지면, 수십, 수백 개의 GPU를 연결해야만 겨우 구동할 수 있습니다. 하지만 여러 GPU를 엮으면 그만큼 데이터 통신에 의한 지연 시간이 늘어나 효율이 떨어집니다. 세레브라스는 ‘초기 비용이 비싸더라도, 거대한 단일 칩으로 외부와의 통신 시간을 없애는 것이 결국 더 빠르고 효율적’이라는 대담한 베팅을 한 것입니다. 이는 여러 장비로 분산 처리하는 대신, 강력한 단일 장비로 모든 것을 해결하겠다는 접근법입니다.

직접 체험하는 압도적 성능과 새로운 가능성
이 놀라운 속도는 현재 세레브라스 홈페이지 데모를 통해 누구나 직접 체험할 수 있습니다. 거대 언어 모델인 라마(Llama) 70B 모델조차 막힘없이 실시간으로 답변을 쏟아내는 것을 보면 감탄이 절로 나옵니다. 이러한 속도는 단순히 답변을 빨리 받는 것 이상의 의미를 가집니다. AI에게 복잡한 질문을 여러 단계에 걸쳐 던지는 ‘체인 오브 소트(Chain-of-Thought)’ 같은 고급 프롬프트 기법을 지연 시간 없이 활용할 수 있게 됩니다. 즉, ‘속도’가 AI 답변의 ‘품질’과 ‘정확도’를 높이는 핵심 열쇠가 되는 것입니다. 이는 기존에는 상상할 수 없었던 새로운 AI 애플리케이션의 등장을 예고합니다.

넘어야 할 산: 비용, 전력, 그리고 생태계
물론 세레브라스 앞에는 해결해야 할 과제도 많습니다. 웨이퍼 한 장당 2천만 원이 넘는 비싼 생산 단가, 단 하나의 결함이 칩 전체에 영향을 미칠 수 있는 수율 문제, 그리고 23kW에 달하는 막대한 전력 소모는 큰 부담입니다. 또한, 엔비디아가 수십 년간 구축해 온 강력한 ‘CUDA’ 소프트웨어 생태계와 경쟁하는 것도 쉽지 않은 일입니다. 하지만 WSE-3는 엔비디아가 할 수 없는 영역에서 압도적인 성능을 보여주며 AI 칩 설계의 새로운 가능성을 증명했습니다. 당장 엔비디아의 아성을 무너뜨리긴 어렵겠지만, AI 기술의 발전에 따라 세레브라스와 같은 혁신적인 아키텍처가 시장의 중요한 한 축을 담당하게 될 날을 기대해볼 만합니다.