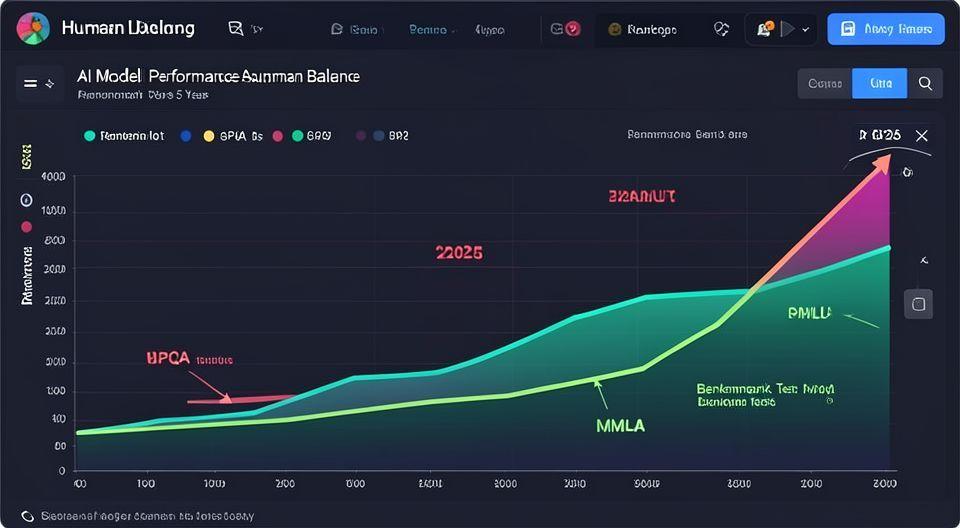
📈 AI 모델 성능, 인간 기준선을 넘어서다
스탠포드 AI 리포트에 따르면 2026년 현재 AI 모델들은 GPQA, MMLU 등 주요 벤치마크에서 인간 전문가의 기준선을 압도적으로 넘어섰습니다. 특히 PhD 수준의 과학 질문에서 인간보다 뛰어난 성능을 보이며, 지난 5년간 발전 속도가 가파르게 상승했음을 확인할 수 있습니다. 💡 클로드 오퍼스 4.6과 같은 최신 모델들은 벤치마크 점수에서 지속적인 향상을 기록하고 있습니다.

🔍 AI 벤치마크의 한계와 테스트 오염 문제
하지만 AI 성능을 평가하는 벤치마크 자체가 제 역할을 못하고 있다는 지적이 늘고 있습니다. 많은 벤치마크들이 컨텐미네이션 문제나 프롬프팅 기법으로 인해 실제 모델 능력을 정확히 반영하지 못하는 경우가 많죠. 📝 이제는 단순한 점수 비교보다 실제 사용 환경에서의 성능 평가가 더 중요해지고 있습니다.
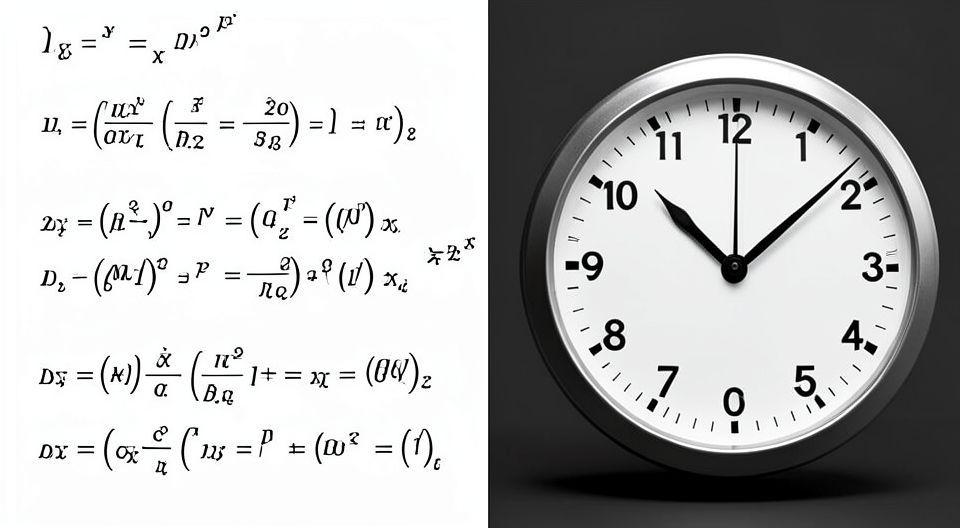
⚙️ AI의 불균형 발전: 수학 천재 vs 시계 읽기 초보
흥미롭게도 AI는 수학 올림피아드에서 금메달을 따는 반면, 아날로그 시계 읽기에서는 50% 정답률에 그치는 모습을 보입니다. 이는 AI가 특정 영역에서는 극도로 뛰어나지만, 다른 영역에서는 인간보다 훨씬 뒤처지는 불균형 발전을 겪고 있음을 보여줍니다. ✨ 클락 QA 테스트에서 AI는 시간 추론 능력이 부족하며, 현실 세계 연결이 아직 불안정한 모습을 드러냅니다.

💡 에이전트 AI의 부상: 실제 작업 수행 능력
채팅을 넘어 실제 작업을 수행하는 에이전트 AI의 성능이 눈에 띄게 향상되었습니다. OS 월드 테스트에서 AI는 컴퓨터 환경에서의 작업 수행 정확도가 66.3%까지 상승했으며, 웹 아레나에서도 인간과 유사한 수준의 상호작용 능력을 보여주고 있습니다. 🔍 이제 AI는 단순 대화가 아니라 파일 조작, 앱 제어, 웹 작업 등 종단간 업무를 처리할 수 있는 수준에 도달했습니다.

📌 물리 세계의 도전: 로봇과 자율주행의 현실
하지만 물리 세계로 나서면 AI의 성능 편차가 더욱 두드러집니다. 로봇 작업에서는 제한된 환경에서는 90% 성공률을 보이지만, 복잡한 가정 작업에서는 10% 미만의 성공률에 그치는 경우가 많죠. ⚙️ 반면 자율주행 분야에서는 웨이모와 아폴로고 같은 서비스가 상용화되며 특정 영역에서의 실용적 적용이 가능해지고 있습니다.
✅ 핵심 요약 Q&A
Q: AI 모델 성능은 실제로 인간을 넘어섰나요? A: 특정 벤치마크에서는 PhD 수준을 넘어서지만, 모든 영역에서 균일하게 뛰어난 것은 아닙니다. Q: AI 평가의 가장 큰 문제는 무엇인가요? A: 기존 벤치마크가 실제 능력을 제대로 반영하지 못하는 테스트 오염과 측정 한계입니다. Q: AI는 어떤 영역에서 특히 뛰어난가요? A: 수학 문제 해결, 구조화된 디지털 작업, 특정 에이전트 업무에서 인간 수준을 넘어서고 있습니다. Q: AI의 가장 큰 약점은 무엇인가요? A: 아날로그 정보 해석, 현실 세계 복잡 작업, 장기 맥락 유지 능력에서 아직 한계를 보입니다. Q: 앞으로 AI 성능 평가는 어떻게 변해야 하나요? A: 단순 점수 비교보다 특정 조건과 환경에서의 실제 작업 성공률 평가가 중요해질 것입니다.


