
💡 구글 TPU 8세대, AI 인프라의 새로운 승부수
구글 TPU 8세대가 등장하면서 AI 인프라 경쟁의 양상이 더욱 뜨거워지고 있습니다. 이제 AI 반도체 전쟁은 단순히 칩 하나의 성능을 넘어, 전체 시스템을 어떻게 효율적으로 구축하고 운영하느냐의 문제로 진화하고 있죠. 구글은 이번에 학습 전용 ‘TPU AT’와 추론 전용 ‘TPU 8i’를 공개하며, 각 워크로드에 최적화된 접근 방식을 선보였습니다. 이는 엔비디아의 전략과도 유사한 부분들이 있어, AI 기술 발전의 방향성을 엿볼 수 있는 중요한 지표가 됩니다. 🚀
🔍 학습(AT)과 추론(8i)의 분리: 왜 중요한가요?
TPU 8세대가 학습과 추론으로 나뉜 이유는 두 작업의 요구사항이 근본적으로 다르기 때문입니다. AI 모델을 만드는 ‘학습’은 방대한 데이터를 끊임없이 처리하며 모델 파라미터를 조정해야 하기에 장시간 안정적인 연산 능력이 중요해요. 📚 반면, 이미 만들어진 AI 모델에 질문하고 답을 얻는 ‘추론’은 사용자의 동시 요청에 대한 즉각적인 반응 속도(레이턴시)와 긴 문맥을 효율적으로 처리하는 능력이 핵심입니다. 구글은 이러한 차이를 명확히 인지하고 각 영역에 특화된 TPU를 설계함으로써 최적의 효율을 추구하고 있는 것이죠.
⚙️ 구글의 ‘AI 하이퍼 컴퓨터’ 전략과 엔비디아와의 비교
구글은 TPU 8세대를 통해 소프트웨어, 하드웨어, 쿨링, 에너지까지 모두 결합된 ‘AI 하이퍼 컴퓨터’라는 시스템 개념을 강조합니다. 이는 엔비디아가 ‘AI 팩토리’라는 용어로 시스템 통합을 강조하는 것과 같은 맥락에 있어요. ✨ 젠슨 황 엔비디아 CEO는 TPU가 특정 용도에만 특화되어 범용성이 떨어진다고 비판했지만, 구글은 자사의 특정 AI 모델(Gemini, JAX 등) 워크로드에 맞춰 최적화된 TPU가 오히려 비용 효율적이고 강력한 강점이 될 수 있다고 보고 있습니다. 폐쇄적이라기보다는 자사 환경에 최적화된 수직 통합의 강점을 극대화하는 전략인 셈이죠.
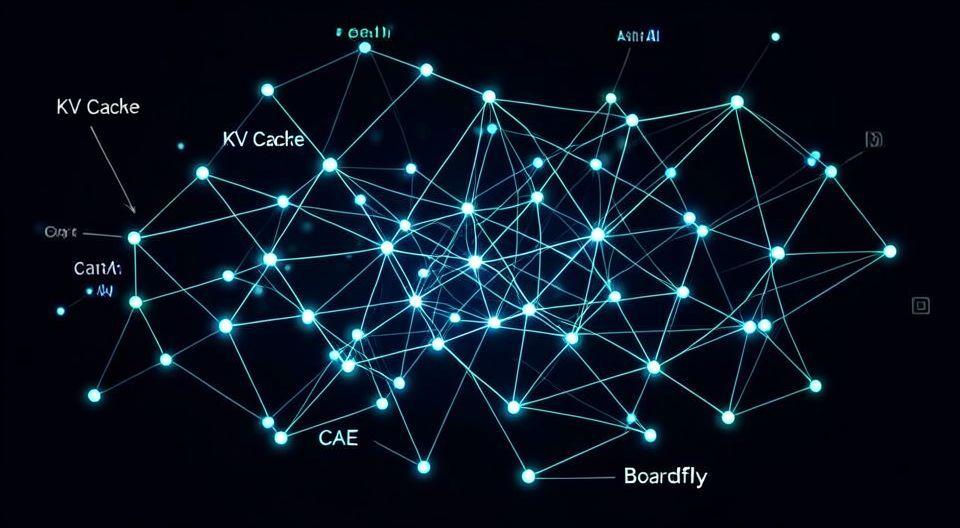
📈 TPU 8i, 추론 성능 극대화를 위한 핵심 기술
TPU 8i는 추론 성능을 극대화하기 위해 여러 혁신적인 기술을 도입했습니다. 핵심은 ‘KV 캐시’를 위한 대용량 S램, 칩 간 통신 지연을 줄이는 ‘CAE(Collective Operation Engine)’, 그리고 네트워크 토폴로지를 최적화한 ‘보드플라이(Boardfly)’입니다. 💨 특히 KV 캐시는 AI가 긴 문맥을 기억하고 효율적으로 참조하여 답변을 생성하는 데 필수적인 요소이며, CAE는 여러 TPU 칩이 협력하여 복잡한 추론 작업을 처리할 때 발생하는 통신 병목을 해결합니다. 보드플라이는 칩 간 연결 거리를 획기적으로 줄여 전체 시스템의 레이턴시를 최소화합니다.

⚡️ 초연결 시대를 위한 네트워크 & 스토리지 혁신
구글은 TPU 8세대와 함께 ‘비르고(Virgo)’ 네트워크와 ‘TPU 다이렉트 스토리지’를 통해 AI 인프라의 전체적인 효율성을 높였습니다. 비르고 네트워크는 수십만 개의 TPU를 하나의 거대한 클러스터로 묶어 초고속 통신을 가능하게 합니다. 🔗 또한, TPU 다이렉트 스토리지는 CPU의 개입 없이 SSD에서 HBM으로 데이터를 직접 전송하여 데이터 병목 현상을 줄입니다. 이는 AI 가속기가 데이터를 기다리는 시간을 없애고, 전체 시스템의 생산성을 비약적으로 향상시키는 중요한 발전이라고 볼 수 있습니다.

🎯 특화형 TPU, 약점 아닌 강점!
TPU가 구글의 특정 워크로드에 특화되었다는 점은 결코 약점이 아닙니다. 오히려 구글의 AI 모델과 컴파일러 스택에 최적화된 설계 덕분에 엔비디아 GPU보다 특정 구간에서 더 높은 효율성과 전력 대비 성능을 달성할 수 있습니다. 💰 하이퍼스케일러 기업들 입장에서는 자신들의 핵심 애플리케이션에 맞는 특화형 반도체가 범용 칩보다 장기적으로 운영 비용을 절감하고 성능을 극대화하는 데 훨씬 유리합니다. AI 인프라의 싸움은 이제 전체 시스템을 얼마나 잘 ‘설계’하느냐에 달려있으며, 구글은 이 분야에서 자신만의 강력한 강점을 구축하고 있는 것이죠.

✅ 핵심 요약 Q&A
Q: 구글 TPU 8세대의 가장 큰 특징은 무엇인가요? A: 학습 전용 TPU AT와 추론 전용 TPU 8i로 분리되어 각 워크로드에 최적화된 성능을 제공하는 것입니다. Q: 구글은 AI 반도체 경쟁에서 어떤 전략을 취하고 있나요? A: 하드웨어, 소프트웨어, 네트워크, 스토리지를 아우르는 ‘AI 하이퍼 컴퓨터’라는 풀스택 수직 통합 전략을 통해 전체 시스템 효율을 극대화하고 있습니다. Q: TPU 8i의 추론 성능을 높이는 주요 기술은 무엇인가요? A: KV 캐시를 위한 대용량 S램, 칩 간 통신을 가속하는 CAE, 최적화된 보드플라이 네트워크 토폴로지 등이 핵심입니다. Q: TPU의 특화형 설계가 약점으로 작용할까요? A: 아닙니다. 구글의 특정 AI 워크로드에 최적화되어 오히려 높은 효율성과 비용 절감 효과를 가져다주는 강점입니다.


